

MoCoSFL: CHO PHÉP HỌC TẬP TỰ GIÁM SÁT CỘNG TÁC GIỮA CLIENTS
Nội dung
1. Giới thiệu
Trong bài viết này, chúng ta sẽ tìm hiểu về thuật toán MoCoSFL, một bài báo nổi bật được công bố trong top 5% tại hội nghị ICLR 2023 [3].
Trước khi đi sâu vào MoCoSFL (Momentum Contrastive Self-Supervised Learning) chúng ta sẽ tìm hiểu về MoCo (Momentum Contrast) và SFL (Split Federated Learning) trước để có cái nhìn toàn diện hơn về MoCoSFL.
2. Thuật toán nền tảng
2.1 MoCo - Momentum Contrast
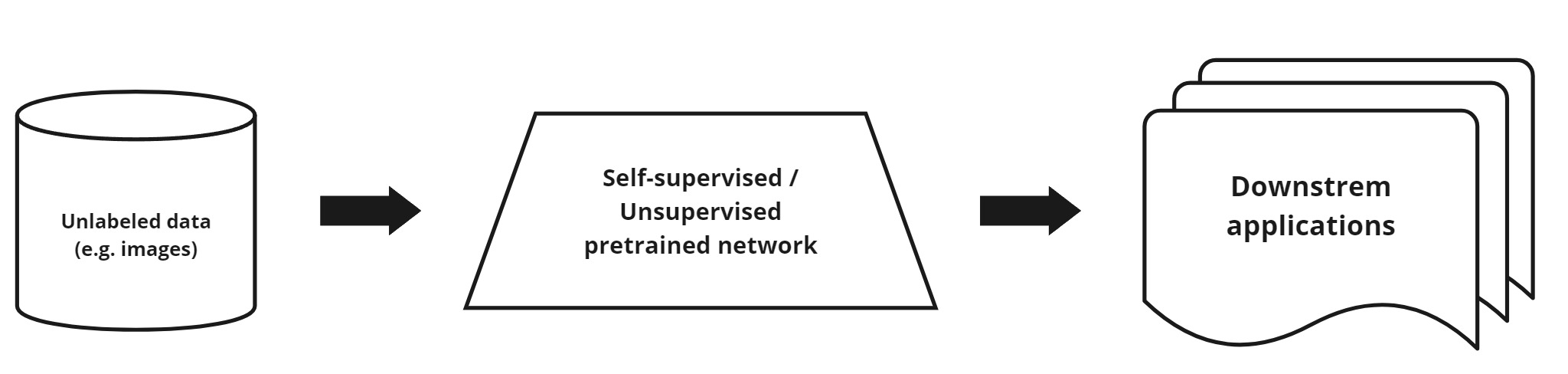 Hình 1. Pipeline of Unsupervised Pretraining and Downstream Applications.
Hình 1. Pipeline of Unsupervised Pretraining and Downstream Applications.
MoCo (Momentum Contrast) là một phương pháp học tự giám sát (Self-Supervised Learning) được sử dụng để học biểu diễn dữ liệu mà không cần nhãn [1]. Trong MoCo, mục tiêu là xây dựng một bộ mã hóa (encoder) có khả năng tạo ra các biểu diễn (representations) ổn định và hiệu quả từ dữ liệu thô như hình ảnh.
Video tham khảo: MoCo (+ v2) - Unsupervised learning in computer vision
MoCo hoạt động dựa trên ý tưởng tạo ra một ngân hàng động (dynamic dictionary) chứa các biểu diễn được cập nhật theo thời gian. Bộ mã hóa được chia thành hai phần: một bộ mã hóa chính và một bộ mã hóa đối chứng (momentum encoder). Bộ mã hóa đối chứng được cập nhật từ từ từ bộ mã hóa chính, giúp giữ được tính nhất quán của các biểu diễn theo thời gian. Bằng cách so sánh các biểu diễn của các cặp dữ liệu tương tự (positive pairs) và không tương tự (negative pairs), MoCo có thể học được các đặc trưng có ý nghĩa của dữ liệu mà không cần nhãn.
Phương pháp này đã đạt được kết quả tốt trong các tác vụ học biểu diễn, đặc biệt trong việc học các biểu diễn hữu ích cho các tác vụ giám sát như phân loại hình ảnh, nhận diện đối tượng.
Tớ có note video trên theo cách tớ hiểu ở đây
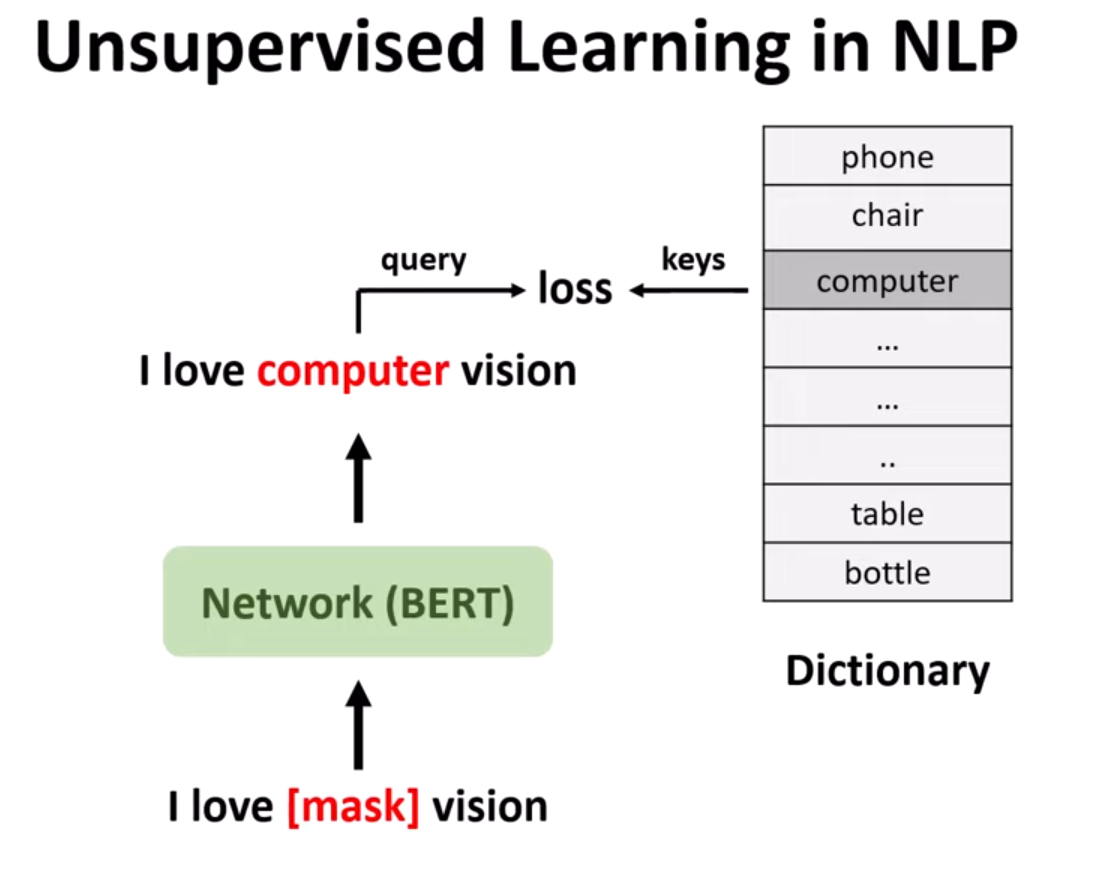 Hình 2. Học không giám sát trong NLP.
Hình 2. Học không giám sát trong NLP.
Chúng ta xem xét học không giám sát trong NLP theo hình trên, quá trình này sẽ như sau. Chúng ta có một mô hình được huấn luyện trước, ví dụ như mô hình BERT. Chúng ta cung cấp cho nó một chuỗi từ làm đầu vào, chẳng hạn như “Tôi yêu [mask token] vision” và đưa chúng vào mô hình. Mô hình của chúng ta có nhiệm vụ dự đoán từ bị thiếu, tức là [mask token] với xác suất cao nhất từ dictionary, và sau đó đưa ra từ thay thế. Để giải quyết vấn đề này, chúng ta có một từ điển chứa tất cả các từ có thể thay thế cho [mask token], và mô hình của chúng ta có trách nhiệm tìm ra từ đúng. Trong trường hợp này, máy tính sẽ áp dụng một hàm mất mát giữa từ bị thiếu hoặc [mask token] và từ tương ứng trong từ điển, chuỗi sau đó sẽ là “Tôi yêu computer vision”.
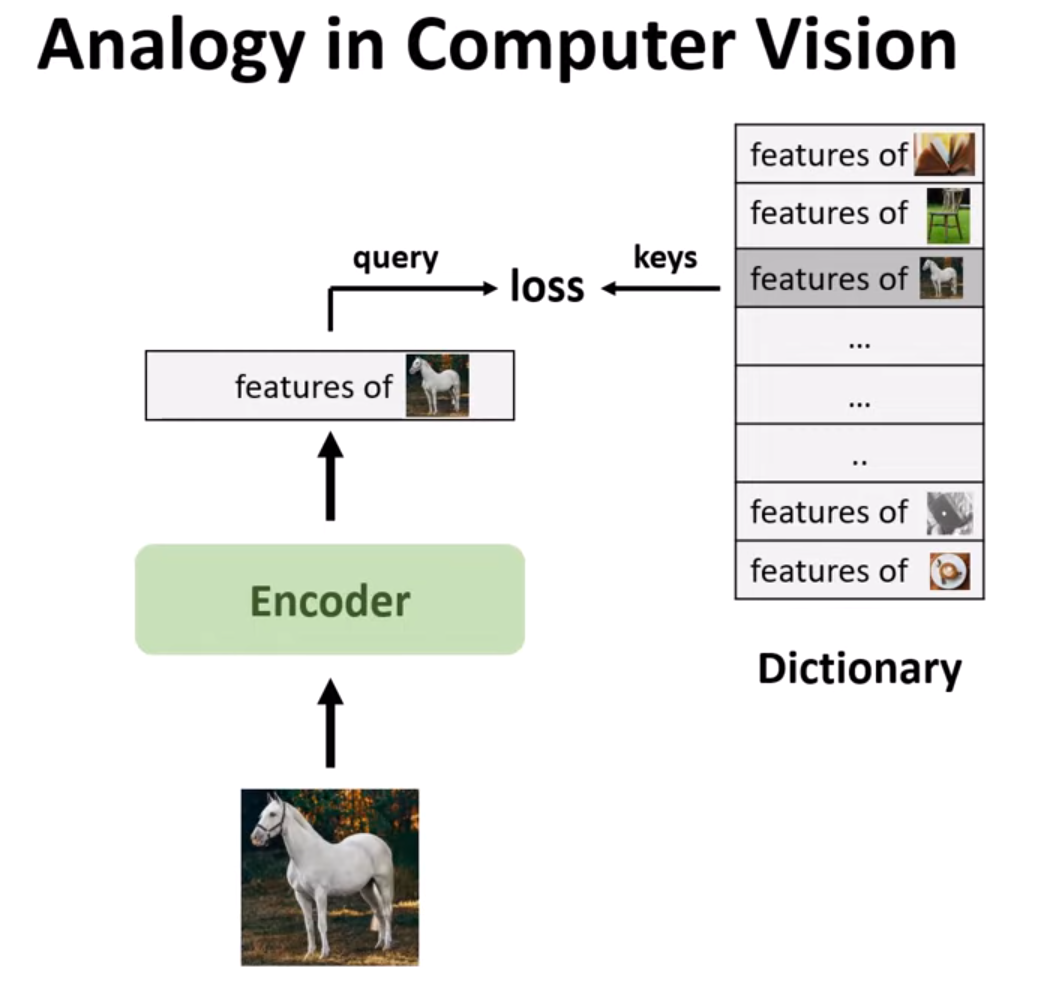 Hình 3. Học không giám sát trong CV.
Hình 3. Học không giám sát trong CV.
Tương tự trong lĩnh vực thị giác máy tính, chúng ta có một hình ảnh đầu vào và đưa nó qua một bộ mã hóa để trích xuất các đặc trưng cấp cao của hình ảnh đó. Sau đó, dictionary của chúng ta sẽ chứa các đặc trưng của tất cả các hình ảnh có thể có. Điều này khác với dictionary trong NLP do sự khác biệt trong không gian tín hiệu của chúng. NLP thường sử dụng các không gian tín hiệu rời rạc (như từ, đơn vị con từ) để xây dựng các từ điển được phân tách, từ đó học không giám sát có thể hoạt động hiệu quả. Trong khi đó, thị giác máy tính đối mặt với thách thức lớn hơn vì tín hiệu thô nằm trong một không gian liên tục và có nhiều chiều, không được cấu trúc theo cách giao tiếp của con người. Nhiệm vụ của chúng ta là tìm ra đặc trưng chính xác từ từ điển này và áp dụng một hàm mất mát giữa Query và Key. Do chỉ có các đặc trưng trích xuất từ hình ảnh, chúng ta sử dụng contrastive learning để giải quyết vấn đề này.
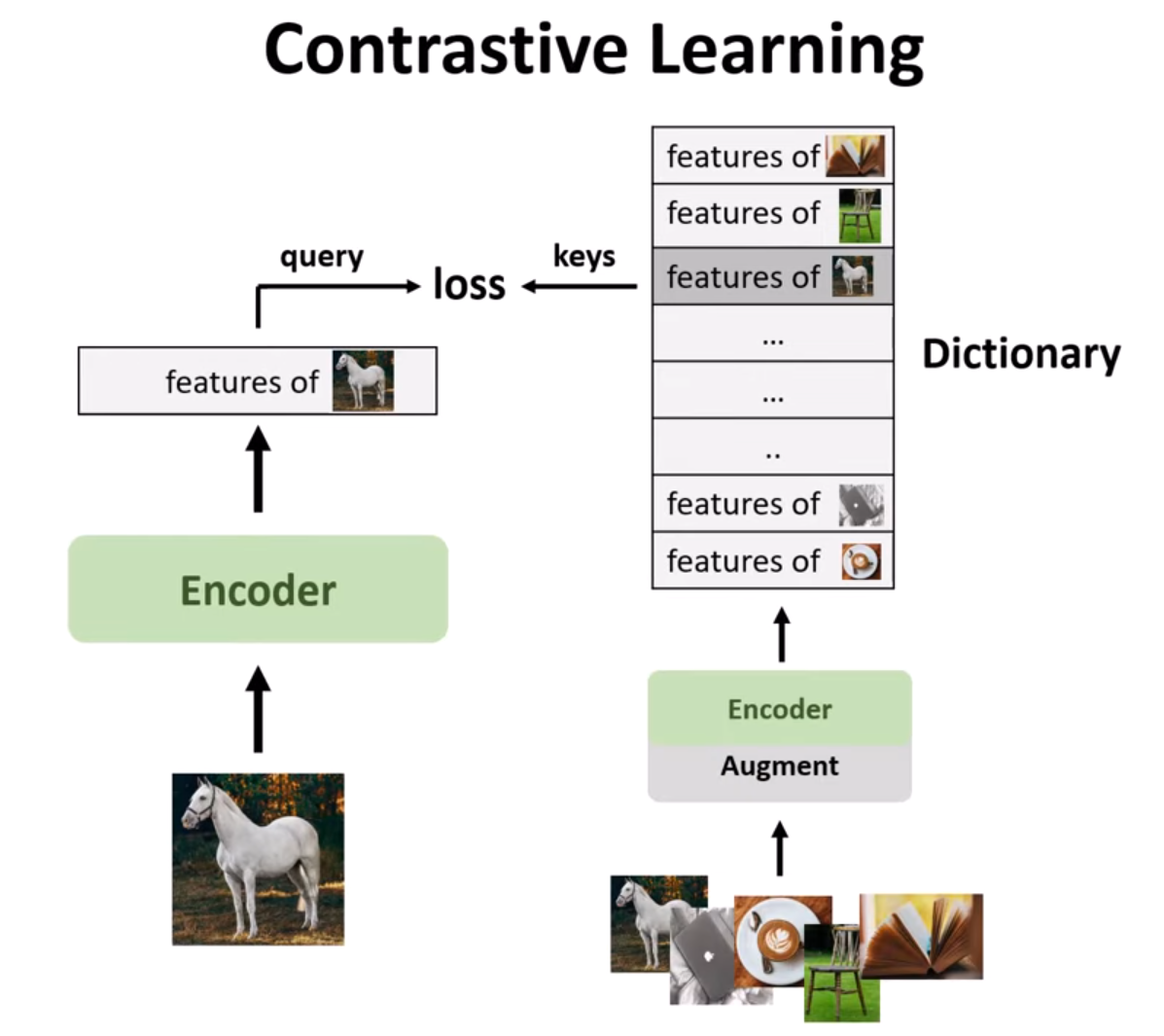 Hình 4. Contrastive learning.
Hình 4. Contrastive learning.
Trong contrastive learning, chúng ta có một batch of images và chỉ trích xuất đặc trưng từ một trong số chúng làm query. Nhưng đối với batch of images đó, chúng ta có thể áp dụng một số kỹ thuật data augmentation như thay đổi màu sắc, phản chiếu, và những kiểu như vậy (như hình bên dưới) rồi truyền chúng vào bộ mã hóa để xây dựng từ điển của chúng ta với những đặc trưng là phiên bản augmented của hình ảnh này. Và chúng ta đã biết đặc trưng nào đến từ phiên bản augmented của hình ảnh query, chúng ta có thể đơn giản chọn từ từ điển của mình và áp dụng một hàm mất mát giữa đặc trưng đó và đặc trưng từ hình ảnh gốc.
 Hình 5. Mô phỏng trực quan data augmentation.
Hình 5. Mô phỏng trực quan data augmentation.
Chúng ta cũng có thể thêm một data augmentation vào hình ảnh gốc và sẽ có 2 augmented image khác nhau cho một hình ảnh duy nhất. Chúng ta so sánh các đặc trưng trích xuất từ chúng để chúng càng giống nhau càng tốt, và điều này thực sự tốt hơn vì trong các epoch khác nhau, chúng ta áp dụng các loại augmentation khác nhau, điều này giúp mô hình của chúng ta trở nên mạnh mẽ hơn với data augmentation và học được tốt hơn từ hình ảnh này.
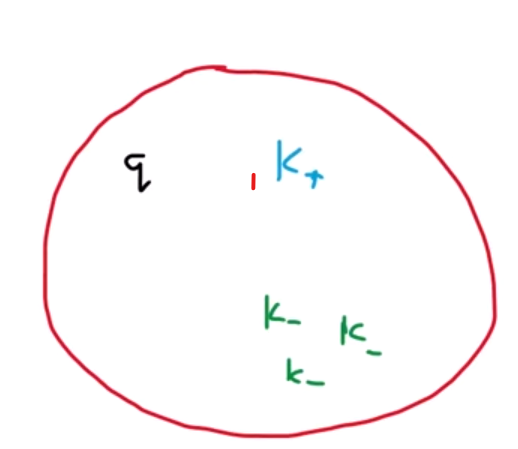 Hình 6. Solution space.
Hình 6. Solution space.
Tiếp theo, chúng ta sẽ xem xét hàm mất mát. Trong contrastive learning, chúng ta có một không gian solution nơi query và tất cả các keys của chúng ta nằm trong đó. Nhiệm vụ của chúng ta là áp dụng một số hàm mất mát để kéo query và positive key về cùng một khu vực của không gian solution để chúng gần nhau và đối với tất cả các negative keys đến từ hình ảnh khác, chúng ta sẽ đẩy chúng ra một khu vực khác.
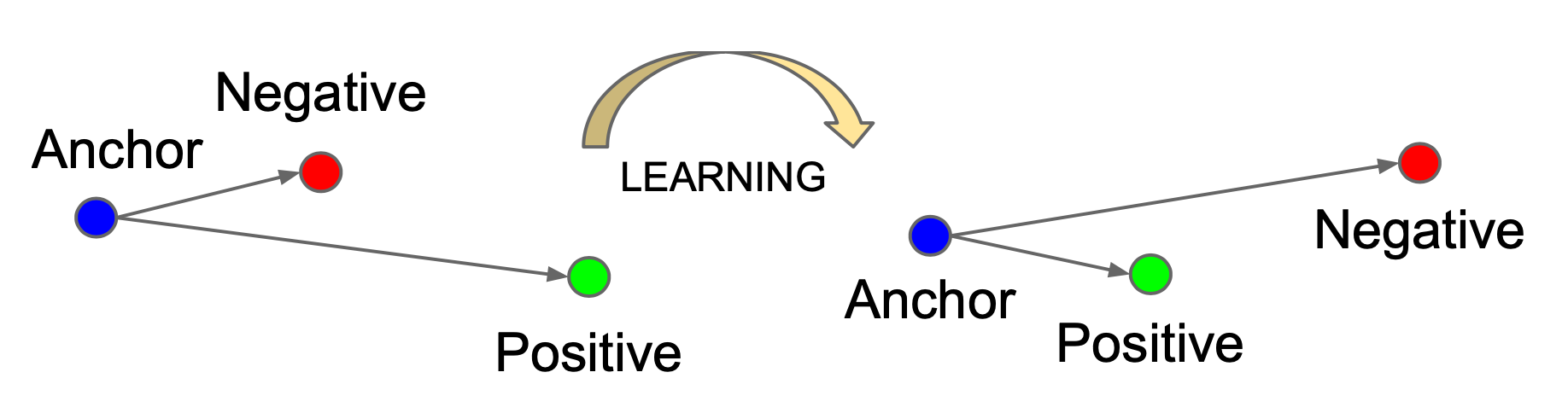 Hình 7. Contrastive learning process.
Hình 7. Contrastive learning process.
Sau khi chúng ta đẩy tất cả các negative keys về một bên và kéo tất cả các positive keys về một bên, chúng ta có thể có một ranh giới quyết định tốt hơn để phân biệt và thực hiện phân loại, ví dụ như vậy. Đây là công thức của hàm mất mát:
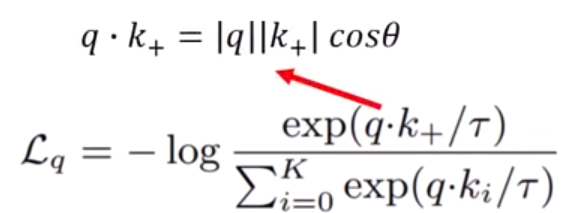 Hình 8. Loss function of contrastive learning.
Hình 8. Loss function of contrastive learning.
Loss function năm bên trong một hàm log âm. Vì hàm log luôn tăng, nên nếu chúng ta muốn giảm log âm, chúng ta cần phải tối đa hóa những gì xảy ra bên trong nó. Để tối đa hóa, chúng ta cần tối đa hóa tử số và tối thiểu hóa mẫu số. Trong tử số, chúng ta có tích vô hướng của positive key và query key là chuẩn của vector và cosine của góc giữa chúng. Chúng ta muốn tối đa hóa thuật ngữ này vì càng lớn, đặc trưng càng gần nhau. Cosine là giá trị giữa 1 và -1 và để tối đa hóa nó, góc giữa query và positive key phải bằng 0, nghĩa là chúng cùng phương. Và ngược lại với mẫu số.
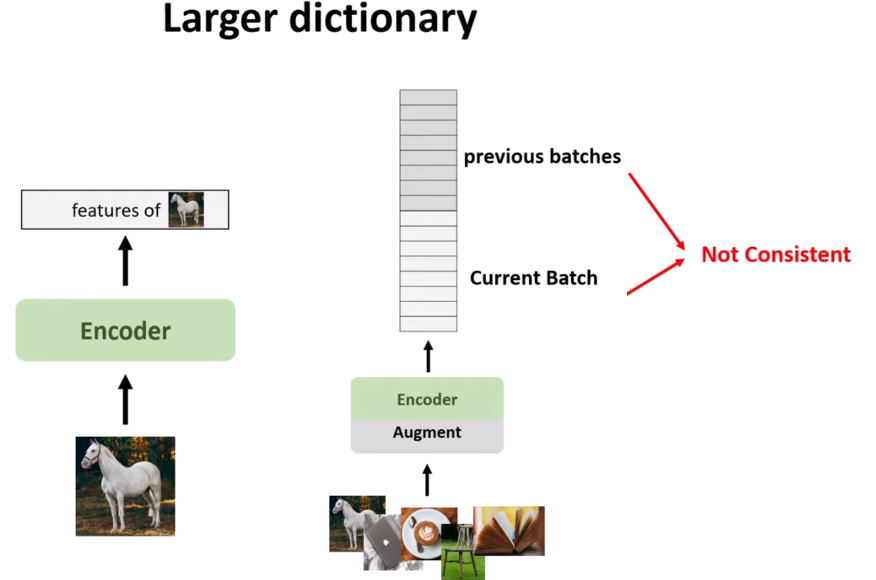 Hình 9. Larger dictionary.
Hình 9. Larger dictionary.
Chúng ta có thể thấy rằng từ điển lớn hơn thì số lượng negative key (và hard negative key) cũng nhiều hơn, và mô hình phải đẩy nhiều negative key hơn từ query, điều này giúp mô hình học và đại diện tốt hơn. Tuy nhiên, có một giới hạn về bộ nhớ GPU, vì vậy chúng ta không thể làm cho batch lớn hơn theo cách thông thường bằng cách tăng kích thước batch. Chúng ta có thể sử dụng một hàng đợi (Queue) để tạo ra một kích thước batch lớn hơn cho việc học, nhưng vấn đề là mỗi stack hoặc kích thước batch được trích xuất từ một bộ mã hóa khác nhau nên các đặc trưng không nhất quán, và đây là khi momentum contrast xuất hiện.
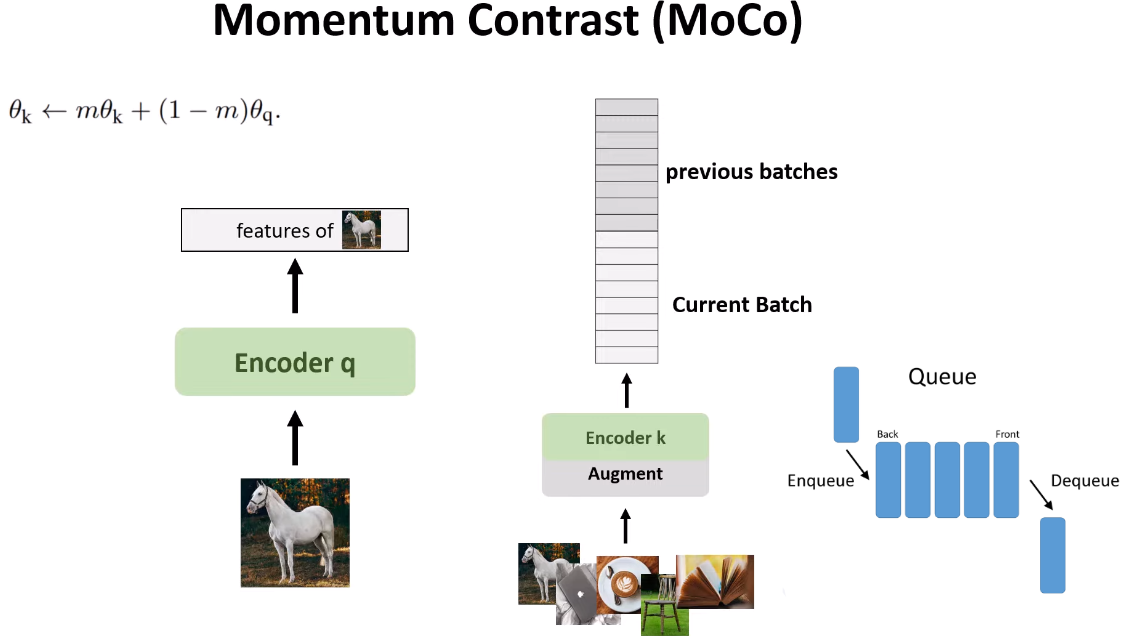 Hình 10. Momentum contrast.
Hình 10. Momentum contrast.
MoCo làm cho từ điển này độc lập với kích thước batch bằng cách áp dụng 2 bộ mã hóa khác nhau, một cho query và một cho key, và sử dụng cập nhật momentum cho bộ mã hóa của key để cập nhật từ từ và làm cho tất cả các stack gần như nhất quán. M gần với 1, như 0.9 hoặc 0.99, để giữ trọng số hiện tại của bộ mã hóa key càng nhiều càng tốt. Các đặc trưng của batch trước và batch hiện tại sẽ khác nhau một chút, nhưng stack đầu tiên và stack cuối cùng sẽ khác nhau rất nhiều. Đó là lý do tại sao kích thước stack nên là 50 là tốt nhất.
2.2 SFL - Split-Federated Learning
Overview về Federated Learning, chi tiết và toàn diện hơn mời bạn đọc tham khảo bài viết về Federated Learning của tớ .
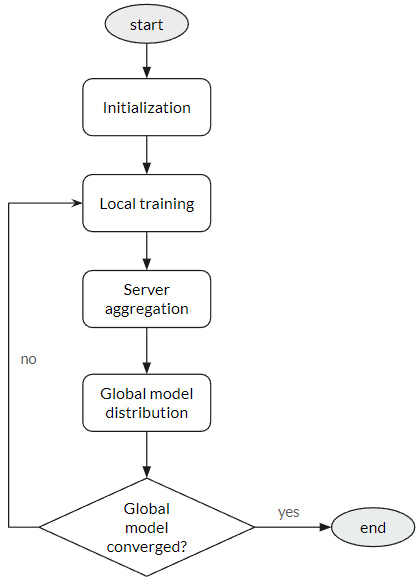 |  |
Nhắc lại một chút về federated learning. Có 5 bước trong quy trình federated learning:
- Khởi tạo: Máy chủ trung tâm khởi tạo một mô hình chia sẻ, được phân phối đến tất cả các thiết bị tham gia.
- Đào tạo cục bộ: Mỗi thiết bị đào tạo mô hình trên dữ liệu cục bộ của nó, sử dụng phương pháp gradient descent ngẫu nhiên hoặc các thuật toán tối ưu hóa khác.
- Tập hợp mô hình: Thiết bị gửi các tham số mô hình đã được cập nhật trở lại máy chủ trung tâm, máy chủ tập hợp chúng để tạo ra một mô hình toàn cầu cải thiện.
- Phân phối mô hình: Máy chủ trung tâm phân phối mô hình toàn cầu đã được cập nhật trở lại các thiết bị.
- Lặp lại: Các bước trên được lặp đi lặp lại cho đến khi mô hình hội tụ về trạng thái tối ưu.
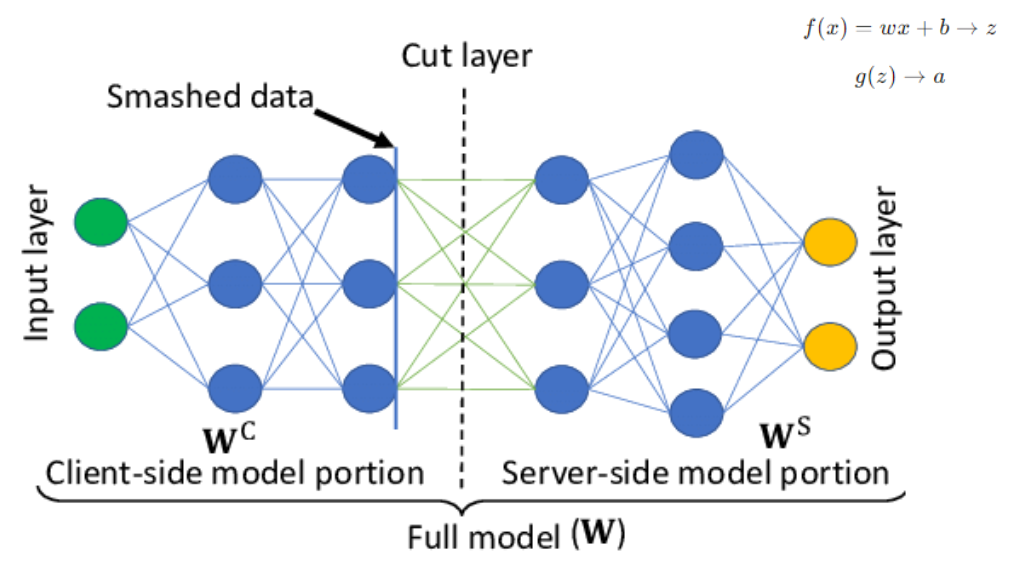 Hình 12. Split Learning.
Hình 12. Split Learning.
Trong split learning, mô hình được chia thành 2 phần: một phần là phần của client (frontend) và phần còn lại là phần của server (backend). Theo forward propagation trong học sâu, sau khi chúng ta đưa dữ liệu vào một lớp, lớp đó sẽ tính toán vector z với weights và biases, sau đó áp dụng một activation function và trả về một vector (chúng ta có thể gọi đây là latent vector). Dữ liệu ở cut layer được gọi là smashed data, đó là latent vector và chúng ta gửi latent vector này đến server để tiếp tục công việc propagation.
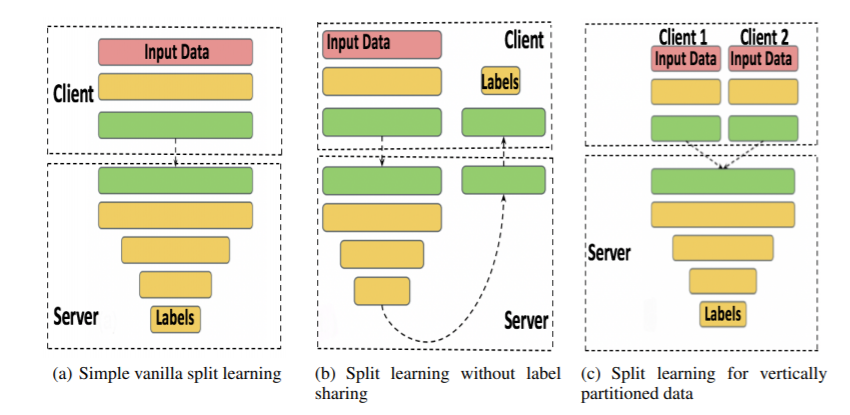 Hình 12. There are 3 types in Split Learning.
Hình 12. There are 3 types in Split Learning.
(a) Simple Vanilla Split Learning
- Mô tả: Trong cấu hình này, mạng nơ-ron được chia giữa phía client và server. Client sẽ xử lý dữ liệu qua các lớp ban đầu và gửi đầu ra trung gian đến server để hoàn thành quá trình truyền tiếp, thực hiện lan truyền ngược và cập nhật trọng số.
- Quá trình:
- Phía client: Client xử lý dữ liệu đầu vào qua một vài lớp đầu tiên của mạng nơ-ron.
- Phía server: Server nhận đầu ra từ các lớp phía client, xử lý qua các lớp còn lại và sau đó tính toán mất mát (loss) bằng cách sử dụng các nhãn (labels).
- Lan truyền ngược: Server tính toán gradient và gửi lại cho client để cập nhật trọng số trong các lớp phía client.
(b) Split Learning without Label Sharing
- Mô tả: Biến thể này được thiết kế để bảo vệ quyền riêng tư bằng cách đảm bảo rằng server không tiếp cận được với nhãn.
- Quá trình:
- Phía client: Client xử lý dữ liệu đầu vào qua một vài lớp đầu tiên và giữ lại các nhãn.
- Phía server: Server xử lý đầu ra từ các lớp phía client qua các lớp của mình và gửi lại các kết quả cuối cùng (mà không tiếp cận được với nhãn).
- Phía client: Client tính toán mất mát (loss) bằng cách sử dụng nhãn và thực hiện lan truyền ngược qua các lớp của client. Sau đó, client gửi các gradient cần thiết cho server để hoàn thành quá trình lan truyền ngược.
(c) Split Learning for Vertically Partitioned Data
- Mô tả: Cấu hình này được sử dụng khi dữ liệu được phân chia giữa nhiều client, mỗi client giữ các đặc trưng khác nhau của cùng một tập dữ liệu (nhưng không phải cùng các mẫu dữ liệu).
- Quá trình:
- Phía client: Mỗi client xử lý phần dữ liệu đầu vào của mình qua một vài lớp đầu tiên.
- Phía server: Server nhận đầu ra từ tất cả các client, gộp lại và xử lý dữ liệu kết hợp qua các lớp còn lại.
- Xử lý nhãn: Server hoặc một trong các client sẽ có quyền truy cập vào các nhãn để tính toán mất mát và lan truyền ngược các gradient đến các client tương ứng.
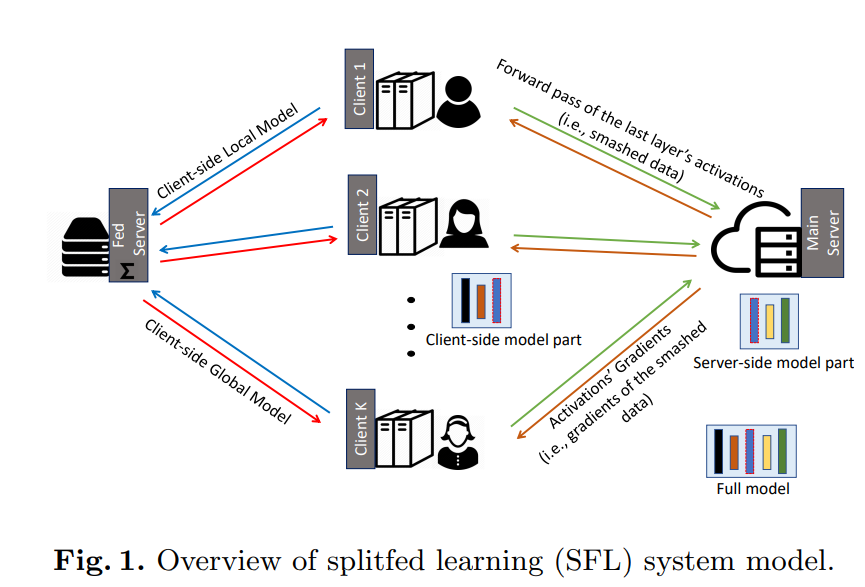 Hình 13. Split Federated Learning.
Hình 13. Split Federated Learning.
Tổng quan về Split Federated Learning (SFL):
- Client-side Local Model (Mô hình cục bộ phía client):
- Mỗi client (Client 1, Client 2, …, Client K) có một phần của mô hình (Client-side Local Model). Phần này bao gồm các lớp ban đầu của mô hình nơ-ron sâu và được chạy trên dữ liệu cục bộ của client.
- Forward Pass (Lan truyền xuôi):
- Mỗi client thực hiện lan truyền xuôi (forward pass) qua các lớp cục bộ của mình, sau đó gửi các kích hoạt (activations) từ lớp cuối cùng, hay còn gọi là smashed data, tới Main Server.
- Main Server (Server chính):
- Server chính nhận dữ liệu smashed từ các client và tiếp tục quá trình xử lý qua các lớp còn lại của mô hình (Server-side model part). Phần mô hình này thường bao gồm các lớp sâu hơn của mạng nơ-ron, nơi các tính toán nặng nhất diễn ra.
- Backpropagation (Lan truyền ngược):
- Sau khi hoàn thành quá trình truyền xuôi và tính toán mất mát (loss), server chính thực hiện lan truyền ngược (backpropagation) để tính toán gradient. Các gradient này, cùng với các kích hoạt (smashed data), được gửi lại cho từng client tương ứng để cập nhật mô hình cục bộ.
- Client-side Global Model (Mô hình toàn cầu phía client):
- Mỗi client cập nhật mô hình cục bộ của mình dựa trên gradient nhận được từ server. Sau khi hoàn tất, mô hình toàn cầu sẽ được tổng hợp và cập nhật trên Fed Server (Server liên kết), sau đó được gửi lại cho các client để bắt đầu vòng học mới.
Mô hình SFL này kết hợp lợi ích của học liên kết và học phân chia, tối ưu hóa việc sử dụng tài nguyên tính toán và đảm bảo bảo mật dữ liệu thông qua việc không chia sẻ dữ liệu thô giữa các client và server chính.
3. Đi sâu vào bài báo
3.1 Problem
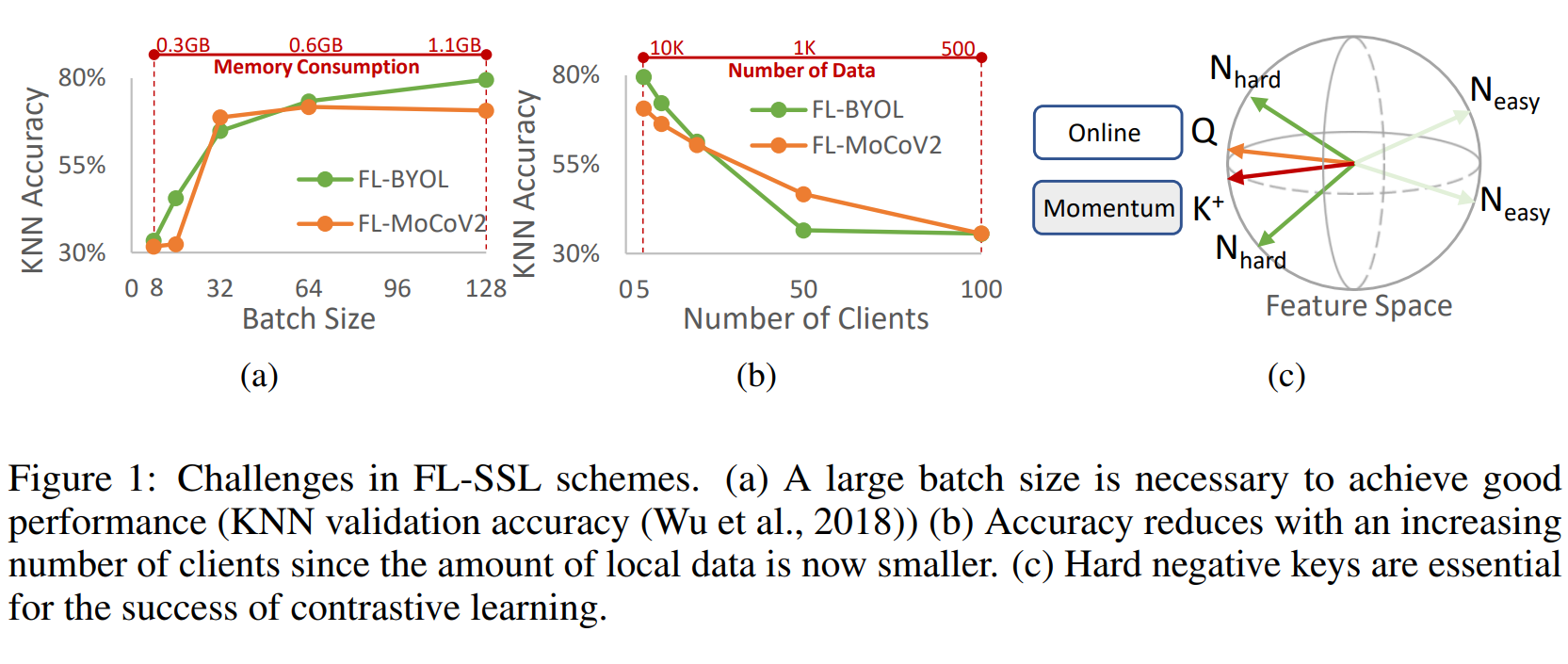 Hình 14. Thách thức trong học liên kết không giám sát (FL-SSL).
Hình 14. Thách thức trong học liên kết không giám sát (FL-SSL).
Hình 1: Các thách thức trong các mô hình FL-SSL.
(a) Kích thước batch lớn cần thiết để đạt hiệu suất tốt: Độ chính xác của KNN tăng lên khi kích thước batch tăng, tuy nhiên điều này cũng làm tăng mức tiêu thụ bộ nhớ (Memory Consumption). Điều này có nghĩa là cần một kích thước batch lớn để đạt được hiệu suất cao trong việc xác thực KNN. Trong hình, khi kích thước batch tăng từ 8 đến 128, độ chính xác KNN của các mô hình FL-BYOL và FL-MoCoV2 đều được cải thiện, nhưng đi kèm với mức tiêu thụ bộ nhớ tăng đáng kể.
(b) Độ chính xác giảm khi số lượng client tăng: Khi số lượng client tham gia tăng lên, lượng dữ liệu cục bộ mà mỗi client nắm giữ sẽ nhỏ hơn, dẫn đến việc giảm độ chính xác. Cụ thể, cả hai mô hình FL-BYOL và FL-MoCoV2 đều cho thấy sự giảm độ chính xác KNN khi số lượng client tăng từ 5 lên 100, do dữ liệu cục bộ bị phân tán và giảm về mặt số lượng.
(c) Các hard negative key (Hard Negative Keys) rất quan trọng cho sự thành công của contrast learning: Trong không gian đặc trưng (Feature Space), việc sử dụng các hard negative key (N_hard) đóng vai trò quan trọng trong việc tối ưu hóa contrast learning. Các negative key dễ (N_easy) không mang lại nhiều thông tin có giá trị và không giúp cải thiện hiệu suất mô hình. Hình ảnh minh họa rằng các mẫu hard negative key là những yếu tố chính giúp tăng cường quá trình học tập trong không gian đặc trưng.
MocoSFL là sự kết hợp sáng tạo giữa SFL-V1 và MoCo-V2.
- Hỗ trợ huấn luyện mini-batch bằng cách sử dụng vector concatenation.
- Sử dụng shared feature memory.
- Cải thiện hiệu suất non-IID bằng cách tăng synchronization frequency.
 Hình 15. Vector concatenation.
Hình 15. Vector concatenation.
3.2 MoCoSFL
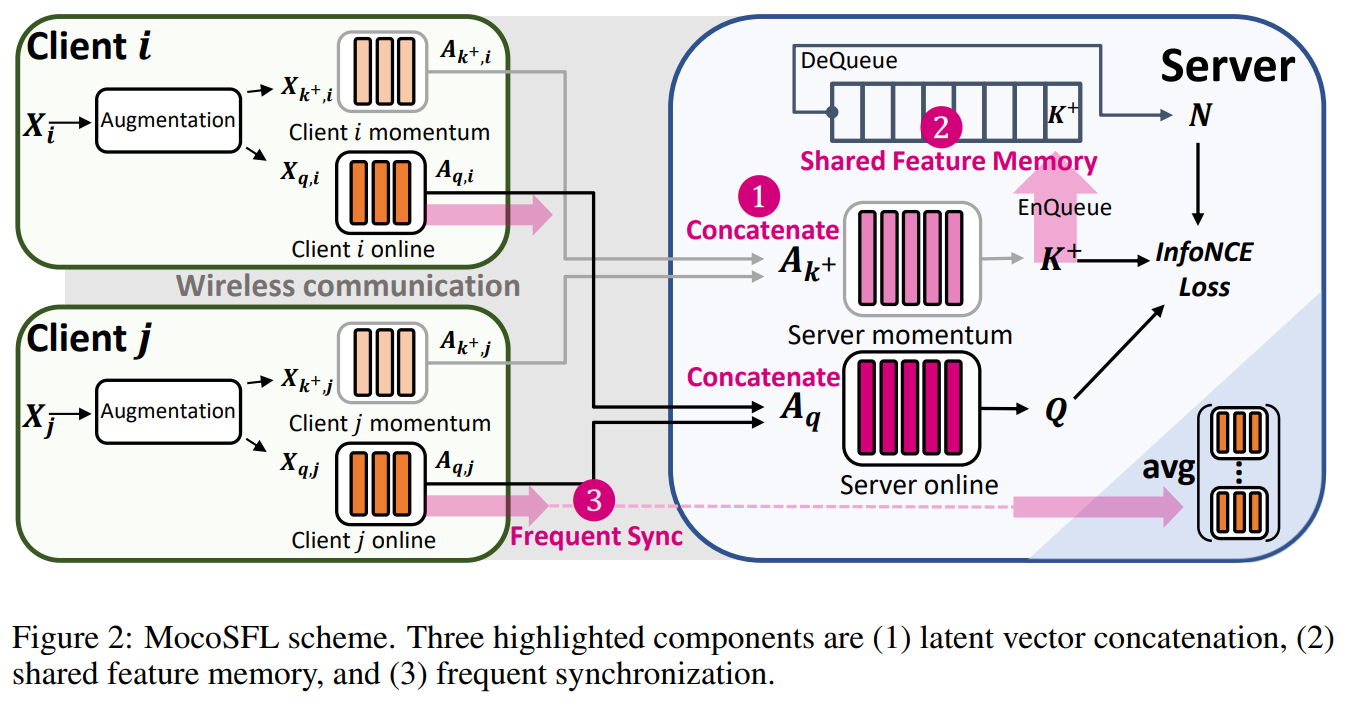 Hình 16. MoCoSFL architecture.
Hình 16. MoCoSFL architecture.
Ảnh trên là kiến trúc của MoCoSFL. Trong mỗi node, dữ liệu đầu vào là X sẽ được augmentation và truyền đến frontend encoder của q và k, sau đó truyền các latent vector này đến server. Server sẽ kết hợp tất cả các latent vector và truyền đến backend encoder k và q để trả về K+ và Q, sau đó tính toán loss. K+ sẽ được đưa vào shared feature memory. Sau khi tính toán loss, họ sẽ sử dụng backpropagation cho backend encoder rồi truyền ngược lại frontend encoder và thực hiện đồng bộ hóa thường xuyên với federated server bằng cách sử dụng FedAvg chẳng hạn để cập nhật mô hình toàn cầu.
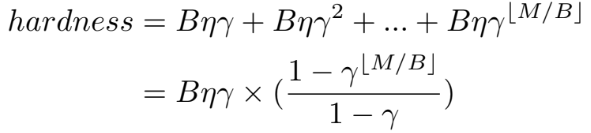 Hình 17. Hardness formula.
Hình 17. Hardness formula.
MoCoSFL giúp giảm bớt yêu cầu về dữ liệu lớn trong học tự giám sát. Để đánh giá độ khó của negative key N trong feature memory, chúng tôi sử dụng thước đo độ tương đồng, đó là tích vô hướng giữa Q và N. Độ khó của một negative key N phụ thuộc nhiều vào độ tương đồng của nó với query key Q hiện tại, với điều kiện rằng N và Q có các nhãn thực khác nhau.
- B: Kích thước batch
- M: Kích thước bộ nhớ
- η: Tốc độ học
- γ: Hệ số hằng số (γ < 1) để độ tương đồng của mỗi batch negative keys trong feature memory bị suy giảm bởi các cập nhật của mô hình.
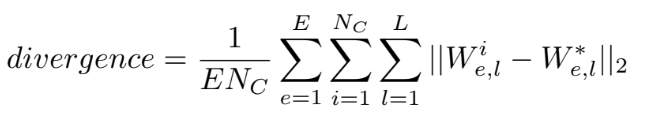 Hình 18. Công thức tính model divergence.
Hình 18. Công thức tính model divergence.
Trong đó:
- \(W^*\): Trọng số trung bình của tất cả các node
- \(W^i\): Trọng số cục bộ của node \(i\)
- \(L\): Số lượng lớp
- \(E\): Tổng số lần đồng bộ hóa
- \(N_C\): Số lượng client
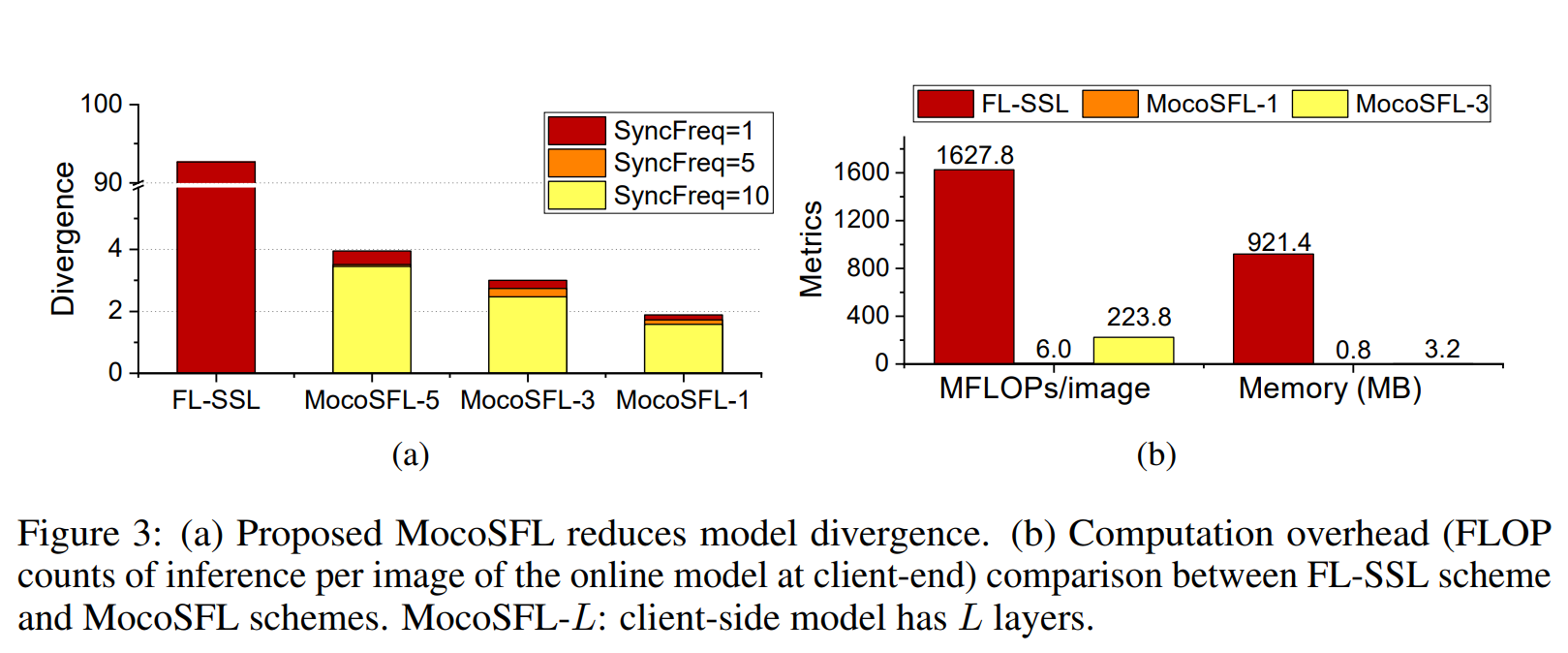 Hình 19. MoCoSFL reduces model divergence.
Hình 19. MoCoSFL reduces model divergence.
MoCoSFL giúp giảm sự phân kỳ của mô hình (model divergence) so với phương pháp FL-SSL, như được minh họa trong biểu đồ (a) của Hình 3:
- Tần số đồng bộ hóa (SyncFreq):
- MoCoSFL sử dụng các tần số đồng bộ hóa khác nhau (1, 5, 10), giúp giảm đáng kể sự phân kỳ so với FL-SSL.
- Khi số lượng lớp trên client-side tăng (MocoSFL-5, MocoSFL-3, MocoSFL-1), độ phân kỳ càng giảm.
- Mức độ phân kỳ:
- FL-SSL có độ phân kỳ cao nhất (~90), trong khi đó MocoSFL-1 chỉ còn dưới 5, với mức tần số đồng bộ hóa cao hơn giúp giảm hơn nữa.
- Cách tính toán Model Divergence:
- Phân kỳ mô hình giữa hai mô hình được tính bằng chuẩn L2 (L2 norm) của sự chênh lệch trọng số.
- Tổng phân kỳ của một hệ thống giữa các client có thể được đo lường bằng cách lấy trung bình phân kỳ trọng số của các mô hình cục bộ.
Với việc giảm model divergence, MoCoSFL tối ưu hóa quá trình học tập phân tán và cải thiện độ chính xác của mô hình.
3.3 TAResSFL - Target-Aware ResSFL
MocoSFL có hai vấn đề chính: chi phí giao tiếp cao do việc truyền các latent vectors và sự dễ bị tổn thương trước Model Inversion Attack (MIA), làm nguy hại đến quyền riêng tư của dữ liệu client.
→ TAResSFL, một phần mở rộng của ResSFL, giải quyết những vấn đề này bằng cách: (1) sử dụng target-data-aware self-supervised pre-training, và (2) đóng băng bộ trích xuất đặc trưng trong quá trình đào tạo SFL. Nó cũng áp dụng thiết kế bottleneck layer để giảm chi phí giao tiếp.
Trong ResSFL, máy chủ thực hiện pretraining chống lại MIA bằng cách sử dụng dữ liệu từ nhiều miền khác nhau. Sau đó, nó gửi mô hình frontend đã được pre-trained đến các client để fine-tuning với SFL.
TAResSFL cải thiện pretraining bằng cách giả định rằng máy chủ có thể truy cập một phần nhỏ (<1%) dữ liệu đào tạo, cùng với một tập dữ liệu lớn từ miền khác. Mô hình frontend đã được pre-trained này cung cấp khả năng chuyển giao tốt hơn và vẫn được giữ nguyên trong quá trình SFL, tránh việc fine-tuning tốn kém.
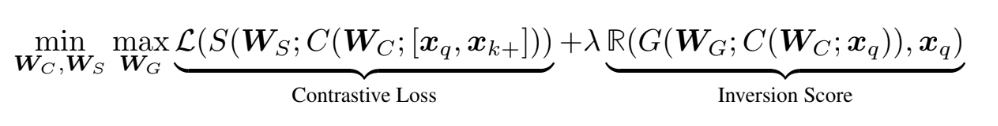 Hình 20. TAResSFL loss function formula.
Hình 20. TAResSFL loss function formula.
- $W_C$ đại diện cho các tham số của bộ trích xuất đặc trưng đối sánh.
- $W_S$ đại diện cho các tham số của mô hình tương đồng, được sử dụng để tính toán độ tương đồng giữa đầu vào đã được tái tạo và đầu vào thực tế.
- $W_G$ đại diện cho các tham số của mô hình tấn công giả lập, chịu trách nhiệm tái tạo lại kích hoạt về trạng thái đầu vào thô tương tự như đầu vào thực tế.
- $x_q$ là đầu vào thực tế.
- $x_k^+$ là một ví dụ tích cực, thường được chọn từ cùng một lớp với $x_q$ để tăng cường độ tương đồng.
- $S$ biểu thị hàm tương đồng, thường sử dụng mất mát đối sánh (contrastive loss).
- $R$ đại diện cho thuật ngữ điều chuẩn, thường kết hợp một thước đo.
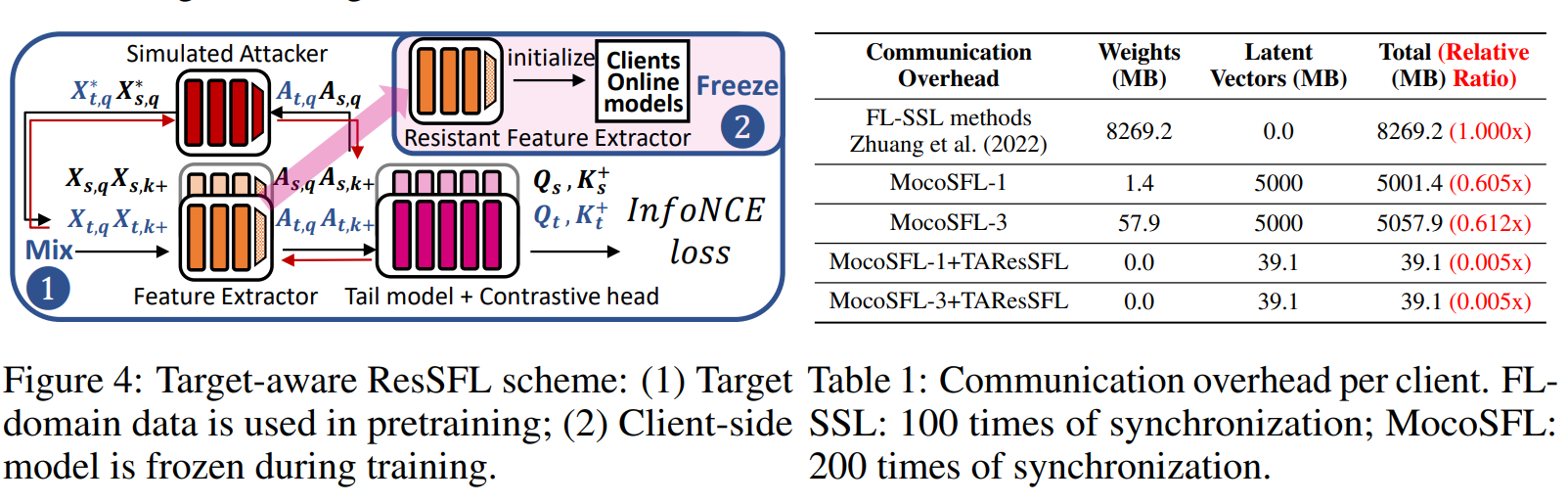 Hình 21. TAResSFL scheme.
Hình 21. TAResSFL scheme.
Sơ đồ Target-aware ResSFL:
- Bước 1: Bộ trích xuất đặc trưng và tấn công giả lập
- Dữ liệu đầu vào $X_{t,q}^$ và $X_{s,q}^$ được truyền qua bộ trích xuất đặc trưng (Feature Extractor).
- Sau đó, các đặc trưng này được truyền qua mô hình tấn công giả lập (Simulated Attacker) để tái tạo thành các kích hoạt $A_{t,q}$ và $A_{s,q}$.
- Bước 2: Mô hình client-side cố định
- Các mô hình client-side online được khởi tạo và sau đó đóng băng (frozen) trong suốt quá trình huấn luyện. Mô hình này đóng vai trò là bộ trích xuất đặc trưng kháng cự (Resistant Feature Extractor).
- Tính toán tổn thất InfoNCE
- Các kích hoạt từ bước 1 được kết hợp với các mô hình đầu đuôi và đầu đối sánh (Tail model + Contrastive head) để tính toán tổn thất InfoNCE, giúp tối ưu hóa sự tương đồng giữa các mẫu tích cực và giảm tương đồng với các mẫu tiêu cực.
Mục tiêu chính của sơ đồ này là sử dụng dữ liệu từ miền đích (Target-domain) để huấn luyện trước mô hình, sau đó đóng băng các trọng số của mô hình client-side trong quá trình huấn luyện, nhằm giảm thiểu chi phí liên lạc và tối ưu hóa quá trình học tập liên kết (federated learning).
4. Thử nghiệm
Cài đặt thí nghiệm:
- Mô phỏng nhiều client sử dụng máy Linux với GPU RTX-3090.
- Sử dụng các tập dữ liệu CIFAR-10, CIFAR-100, và ImageNet 12. Đối với IID, phân chia các tập dữ liệu ngẫu nhiên và đồng đều giữa các client. Đối với non-IID, phân bổ ngẫu nhiên 2 lớp cho CIFAR-10/ImageNet-12 hoặc 20 lớp cho CIFAR-100 cho mỗi client.
- Đào tạo MocoSFL trong 200 epochs với bộ tối ưu hóa SGD (LR khởi đầu: 0.06).
- Đánh giá độ chính xác bằng phương pháp linear probe: đào tạo bộ phân loại tuyến tính trên các đại diện đã được đóng băng. Đơn giản hóa: mô hình đại diện(dữ liệu) → đặc trưng → lớp bộ phân loại tuyến tính để đánh giá khả năng trích xuất mẫu của mô hình đã được pre-trained.
Linear evaluzation: Classifier sau đó được đào tạo bằng cách sử dụng các representations đã được trích xuất làm đặc trưng đầu vào, thường với một lớp tuyến tính đơn giản được thêm vào để thực hiện nhiệm vụ phân loại. Phương pháp này cho phép transfer learning hiệu quả, vì mô hình đã được pre-trained đã học được các đại diện phong phú và hữu ích từ nhiệm vụ ban đầu, có thể được fine-tuned cho nhiệm vụ cụ thể hiện tại.
 Hình 22. Accuracy Performance.
Hình 22. Accuracy Performance.
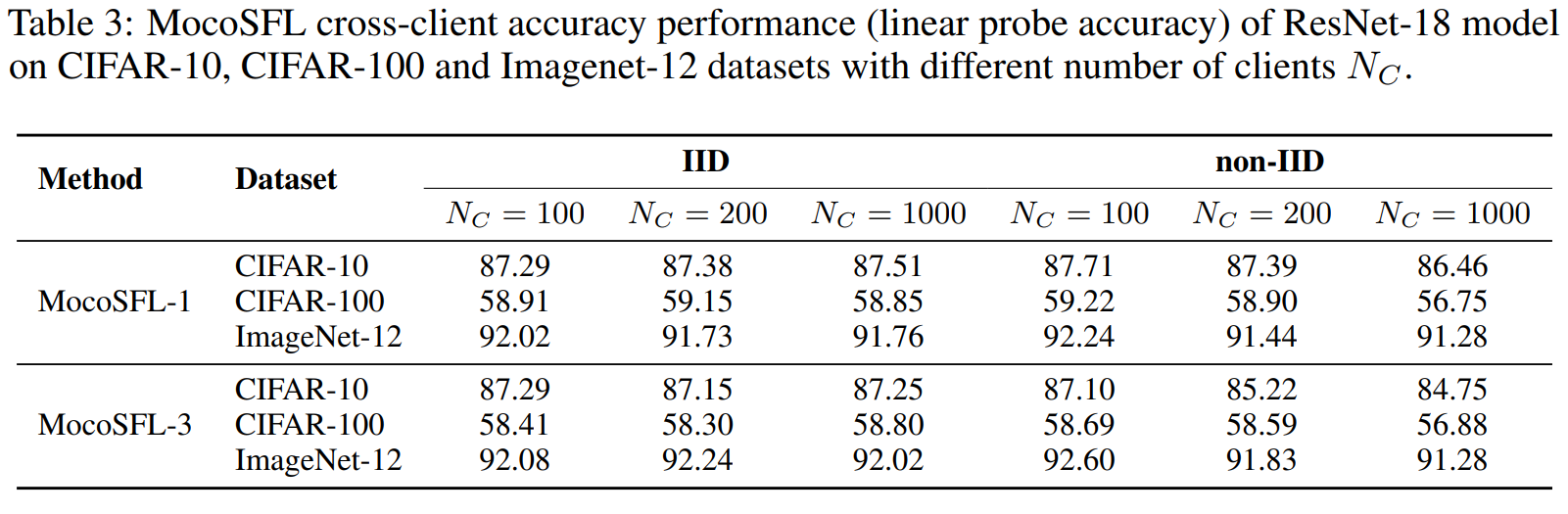 Hình 23. Accuracy Performance.
Hình 23. Accuracy Performance.
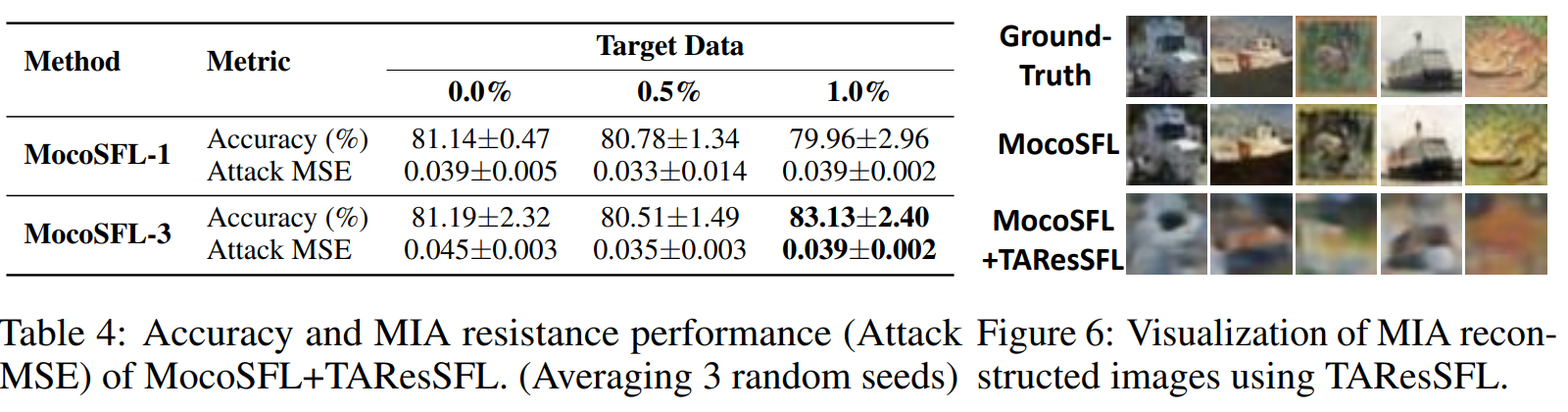 Hình 24. Privacy Evaluation.
Hình 24. Privacy Evaluation.
So sánh chi phí tài nguyên phần cứng của MocoSFL, MocoSFL+TAResSFL (SyncFreq=1/epoch trong 200 epochs), và FL-SSL (E=500, SyncFreq=1 mỗi 5 epoch cục bộ).
- Raspberry Pi 4B với 1GB RAM đóng vai trò là một client thực tế, các client còn lại được mô phỏng trên PC.
- MocoSFL: 1,000 clients, kích thước batch 1, lớp cắt 3.
- FL-SSL: 5 clients, kích thước batch 128.
- Dữ liệu theo mặc định là 2-class non-IID.
- Đánh giá chi phí bằng cách sử dụng ‘fvcore’ cho FLOPs và ‘torch.cuda.memory_allocated’ cho bộ nhớ.
 Hình 25. Hardware demonstration.
Hình 25. Hardware demonstration.
5. Tham khảo
[1] Momentum Contrast for Unsupervised Visual Representation Learning, Kaiming He et al.
[2] SplitFed: When Federated Learning Meets Split Learning, Chandra Thap et al.
[3] MocoSFL: enabling cross-client collaborative self-supervised learning, Jingtao Li et al.
[4] ResSFL: A Resistance Transfer Framework for Defending Model Inversion Attack in Split Federated Learning, Jingtao Li et al.