

Federated Split Learning with Efficient File-Based Gradient Synchronization
This post provides an overview of the motivation and core ideas of the study. Detailed analyses and experimental results are available in the referenced materials below.
Split Federated Learning (SFL) is a framework that combines Split Learning and Federated Learning, originally proposed by C. Thapa et al., with the primary goal of reducing computational overhead on the client side. Despite its advantages, practical deployment of SFL still faces several challenges.
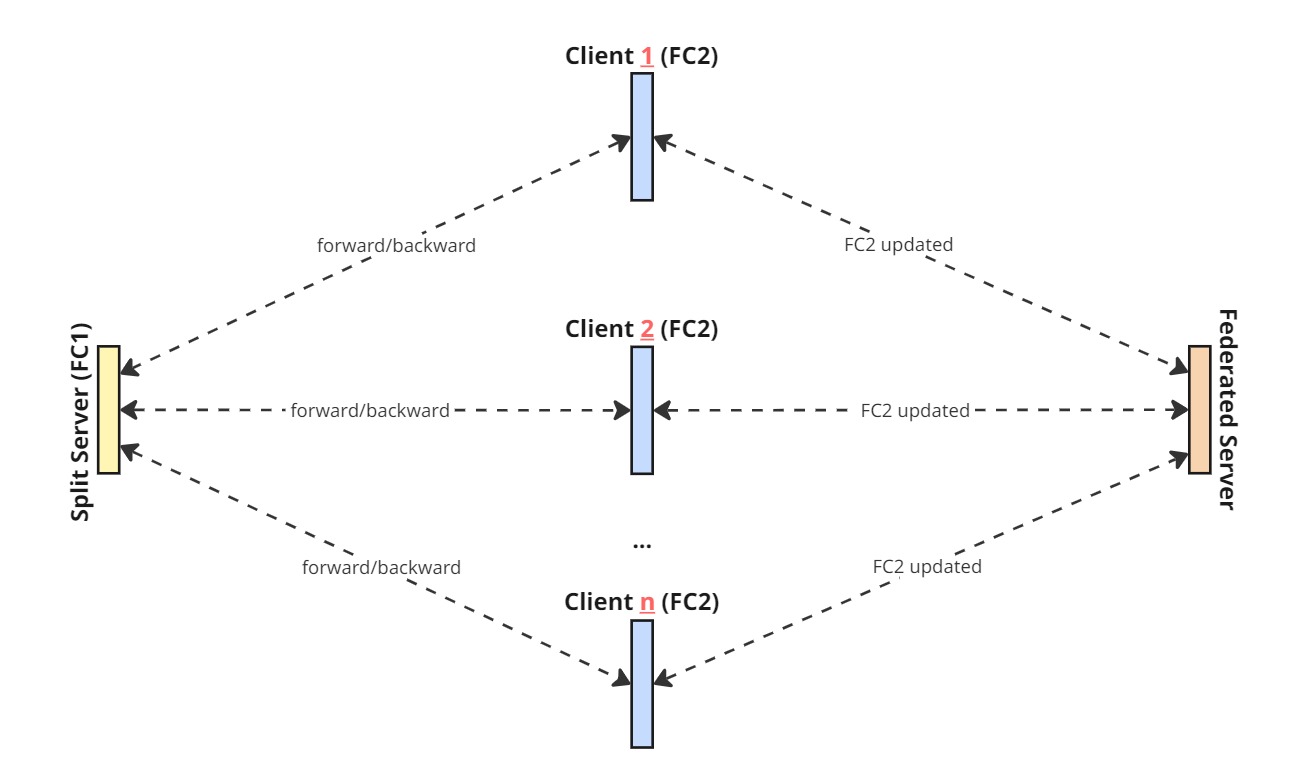 SFL architecture
SFL architecture
In conventional SFL architectures, the Split Server hosts the server-side model and stores intermediate gradients in memory, which requires maintaining training state to update model parameters. As a result, the Split Server becomes a stateful service, making it difficult to deploy in cloud environments based on microservice architectures, where stateless services are preferred for scalability and elasticity.
In this study, we analyze the gradient flow in SFL and observe that server-side parameters can be updated using batch-wise averaged gradients. Specifically, activations and gradients are stored as files to support forward and backward computation. With this mechanism, forward and backward passes can be processed in parallel, while newly generated gradients are accumulated and updated asynchronously, rather than being strictly synchronized at every batch.
This approach enables gradient transmission through simple APIs. In federated settings with many concurrent clients, it helps mitigate bottlenecks and synchronization delays that typically arise when the server must wait for gradients from all participants.
When the Split Server is responsible only for computing forward activations and backward gradients, it can be designed as a stateless application, allowing flexible horizontal scaling and more efficient resource utilization.
Within the scope of this work, we focus on demonstrating the effectiveness of file-based gradient synchronization via APIs. In extended scenarios, gradients can be stored on persistent storage, averaged after each training round to update the server-side model, and then redistributed to all Split Server instances. This design naturally aligns with cloud-native and microservice-oriented systems.
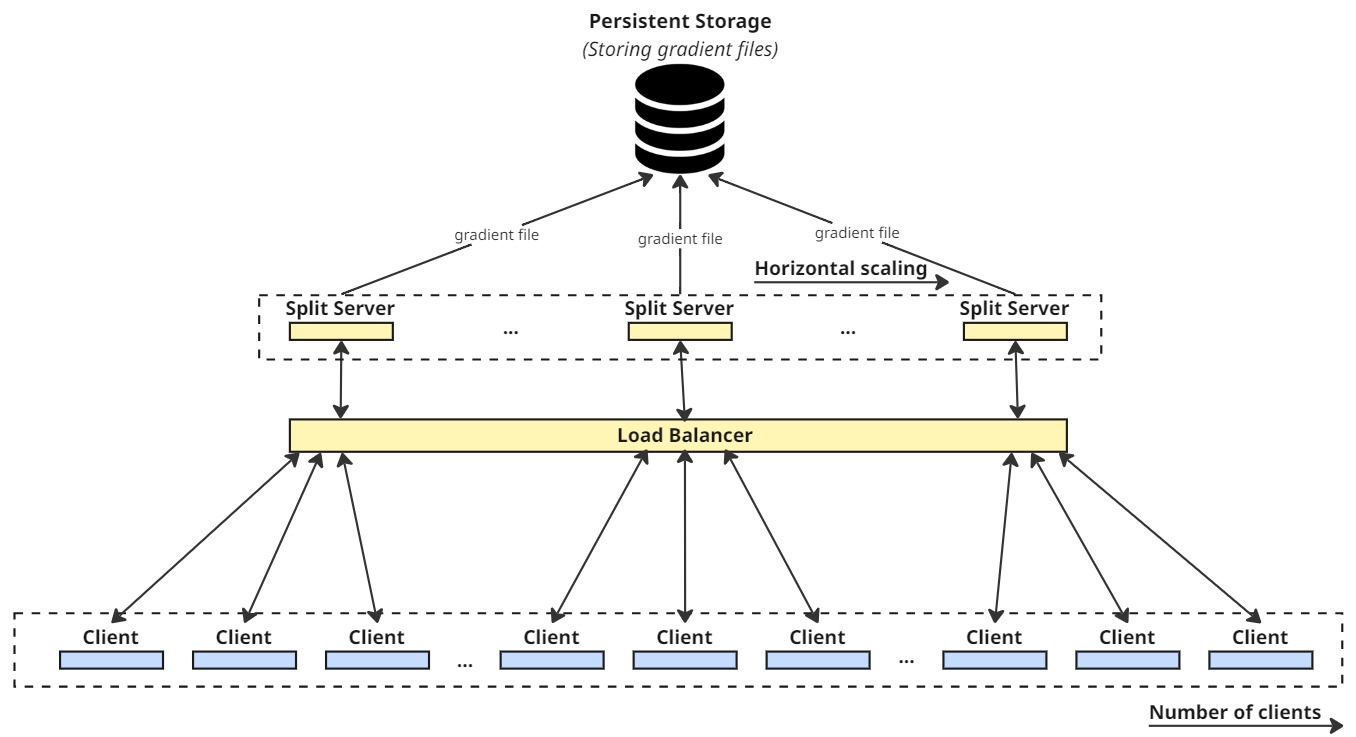 Illustration of the scaling mechanism in SFL when the Split Server is designed as a stateless application, enabling flexible deployment and horizontal scalability in microservice environments.
Illustration of the scaling mechanism in SFL when the Split Server is designed as a stateless application, enabling flexible deployment and horizontal scalability in microservice environments.
Detailed analysis of the gradient flow, system architecture, and experimental results can be found at:
here
Source code used for the experiments:
here